上一篇已經先用resnet26d 速跑了一遍,這一篇看看我們能做什麼努力,讓結果變得更好
主題已經寫了這次的目標,嘗試著用不同的小模型,來看看效果。
所以可以想見,之後的登頂之路要換大模型。
那我也想說,只是單單換模型而已嗎?這樣需要寫一篇筆記?
帶著這個疑問,讓我們看下去吧!
為了方便切換不同的模型,我們將這些步驟寫成一個function 比較容易使用
def train(arch, item, batch, epochs=5):
dls = ImageDataLoaders.from_folder(trn_path, seed=42, valid_pct=0.2, item_tfms=item, batch_tfms=batch)
learn = vision_learner(dls, arch, metrics=error_rate).to_fp16()
learn.fine_tune(epochs, 0.01)
return learn
其中arch 是模型名稱,item就是轉換size 的方法,batch 就是一次要處理幾筆,epochs 就是跑幾次
如我們之前跑的resnet26d,就可以這樣呼叫,把size 轉192*192:
learn = train('resnet26d', item=Resize(192),
batch=aug_transforms(size=128, min_scale=0.75))
在這部分,講師提到了一種名為 ConvNeXt 的模型,並表示他們將嘗試使用這個模型來進行訓練。之所以選擇 ConvNeXt 模型,是因為他注意到在 Kaggle 上的 GPU 使用率仍然很低,這意味著的訓練過程主要受到 CPU 的限制,而不是 GPU。
arch = 'convnext_small_in22k'
learn = train(arch, item=Resize(192, method='squish'),
batch=aug_transforms(size=128, min_scale=0.75))
ConvNeXt 是一種深度學習模型,通常用於計算機視覺任務。在這個情境下,講師選擇了一個叫做 convnext_small_in22k 的 ConvNeXt 模型,這個模型在性能和準確性之間有一個良好的平衡,被認為是一個選擇性能/準確性權衡的良好選擇,然後使用了與之前相似的訓練過程,將圖像大小調整為 192x192 像素,然後應用了數據增強轉換,包括隨機縮放和其他變換,以改進訓練數據的多樣性。
所以我們使用 ConvNeXt 模型來訓練,以期望在保持訓練速度不受太大影響的情況下,提高模型的性能和準確性。
看一下換這個模型結果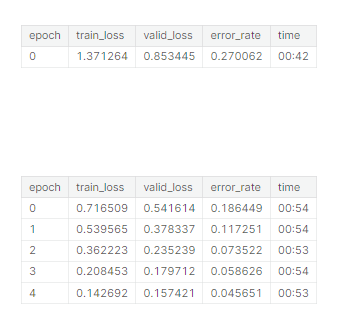
看起來還不錯!
到目前為止,我們透過換模型來優化,但我們也有其他優化方法。
先探討前處理的方法,之前都用Squish。
有以下幾種選擇:
Squish(壓縮):將長方形圖像壓縮成正方形,可能會改變圖像的寬高比。
Crop(裁剪):從長方形圖像中隨機裁剪出一個正方形區域,保持圖像的寬高比。
Padding(填充):在圖像的邊緣添加黑色填充,使其變成正方形。
那我們選擇Pad試試看
dls = ImageDataLoaders.from_folder(trn_path, valid_pct=0.2, seed=42,
item_tfms=Resize(192, method=ResizeMethod.Pad, pad_mode=PadMode.Zeros))
dls.show_batch(max_n=3)
改用pad 來resize後,train看看
learn = train(arch, item=Resize((256,192), method=ResizeMethod.Pad, pad_mode=PadMode.Zeros),
batch=aug_transforms(size=(171,128), min_scale=0.75))
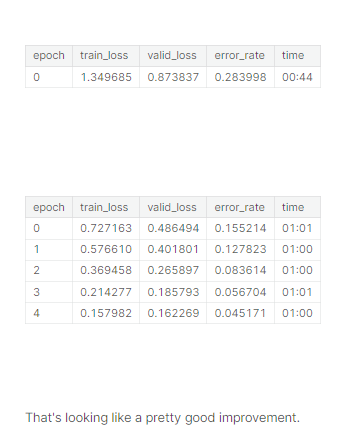
哇竟然有點改進!所以在圖像的前處理上我們是有加強空間的
接下來看看講師還有什麼新招
測試時間增強(Test time augmentation,TTA)
一開始看到這個完全有看沒有懂,查了一下發現他是對於每個要進行預測的圖像,創建多個版本,這些版本是通過數據增強(data augmentation)技術生成的。這些增強版本可以是原始圖像的旋轉、縮放、裁剪、翻轉等變換。
對於每個增強版本,使用已訓練的模型進行預測,獲得一組預測結果
對於每個原始圖像,最終的預測結果可以是所有增強版本的預測結果的平均值或最大值
這個過程的目的是提高模型的性能,因為不同的增強版本可以捕捉到圖像中的不同特徵,進而改善預測結果的準確性
那就先來看一下,「沒有」用TTA的版本
valid = learn.dls.valid
preds,targs = learn.get_preds(dl=valid)
error_rate(preds, targs)
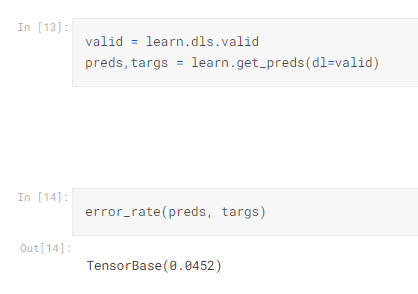
那接下來就使用tta
tta_preds,_ = learn.tta(dl=valid)
error_rate(tta_preds, targs)
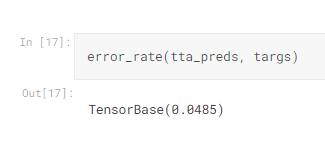
結果竟然有改進!
還有除了TTA,還有沒有別的招術呢?
講師接下來想將模型升級,使用更大的圖像和更多的訓練周期來進行訓練:
首先將圖像的路徑切換回了原始未縮放的圖像,就是說使用未經調整大小的圖像進行訓練。這樣可以提高圖像的解析度
然後使用 12 個訓練周期(epochs),這是為了增加模型的訓練時間,以提高性能
在進行圖像預處理時,講師依然使用了之前成功的方法,即將圖像調整為相同的尺寸,同時應用增強變換,這次的最終圖像尺寸更大
learn = train(arch, epochs=12,
item=Resize((480, 360), method=ResizeMethod.Pad, pad_mode=PadMode.Zeros),
batch=aug_transforms(size=(256,192), min_scale=0.75))
```
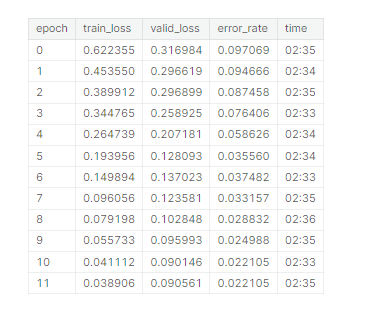
可以看到結果還不錯,那能不能再加入剛才的TTA呢?
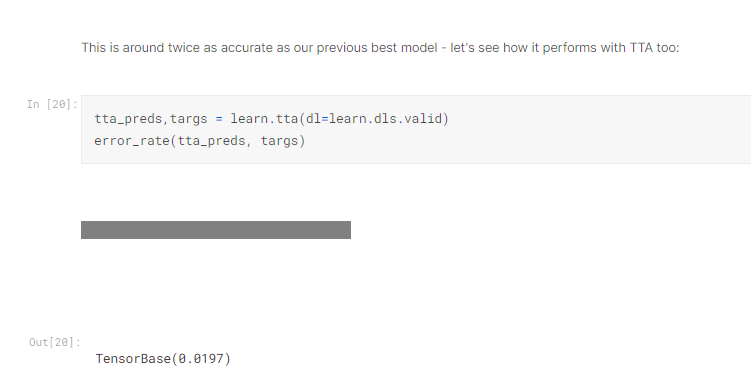
哇賽有顯著的改善! 所以這邊就是今天的新招,
這就完了嗎? 不,講師還有2個notebook 要教我們如何再更完善,我們下一篇再學


 iThome鐵人賽
iThome鐵人賽